You spent millions securing production
Your Test Environments Have None of It.
That’s where your next satisfactory audit finding, or your next breach, is coming from.

![]() What we typically find:
What we typically find:
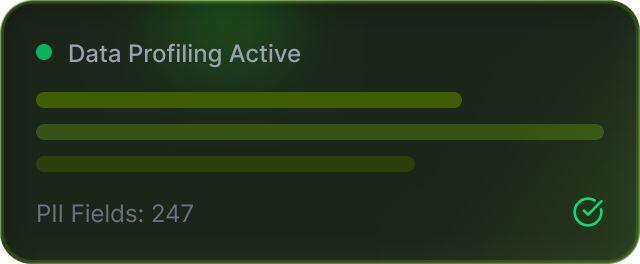
Non-production holds 3–5× more sensitive data than production — with a fraction of the controls. Every copy is a breach surface.
![]()
Full production copies in 4–7 environments
Each with unmasked PII
![]()
Developers with unrestricted access
To real customer records because “they need realistic data”
![]()
No policy on data lifecycle
How long test data lives, who accesses it, or when it’s purged
![]()
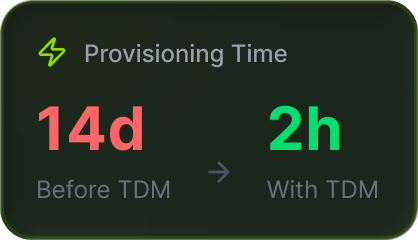
Environment provisioning
Taking 5–14 days per sprint cycle
![]()
Complete TDM Stack for
Regulated Enterprises
From profiling to purging — every capability you need for compliant test data provisioning.
![]() THE DIGITRALY DIFFERENCE
THE DIGITRALY DIFFERENCE
We classify every field against GDPR, HIPAA, PCI DSS and produce a masking policy map before transformation
![]() THE DIGITRALY DIFFERENCE
THE DIGITRALY DIFFERENCE
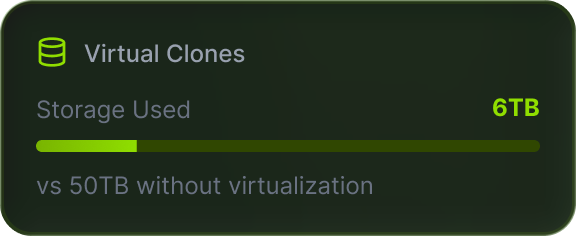
Rule-based extraction preserving foreign keys, business logic, and edge cases. Faster refreshes. Lower storage.
![]() THE DIGITRALY DIFFERENCE
THE DIGITRALY DIFFERENCE
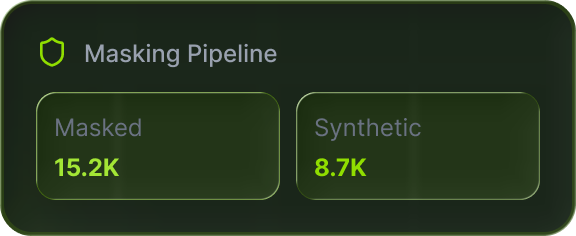
Masking as an automated pipeline, not a one-time project. Schema changes trigger policy updates. Every run is logged and auditable.
![]() THE DIGITRALY DIFFERENCE
THE DIGITRALY DIFFERENCE
Synthetic pipelines producing datasets that pass production validation rules. Format-correct, distribution-accurate, audit-documented.
![]() THE DIGITRALY DIFFERENCE
THE DIGITRALY DIFFERENCE
Virtual database provisioning integrated into CI/CD — every build triggers an automated, masked, right-sized clone.
![]() THE DIGITRALY DIFFERENCE
THE DIGITRALY DIFFERENCE
Automated purge workflows with full audit trails, integrated with data governance tooling. No forgotten environments.
![]()
Practical Cybersecurity
Without Compromise

![]() Airlines & Aviation
Airlines & Aviation
PNR masking, loyalty data subsetting, PSS test environments, IATA compliance
![]() Banking & Fintech
Banking & Fintech
PCI DSS masking, SOX-auditable purging, transaction synthesis, core banking virtualisation
![]() Healthcare
Healthcare
HIPAA PHI masking, synthetic patient data, EHR subsets, HL7/FHIR-compliant pipelines.
![]() Insurance
Insurance
Policyholder anonymisation, claims virtualisation, actuarial synthetic datasets.
![]() Telecom
Telecom
CDR masking, subscriber subsetting, MVNO test provisioning.
![]()
Our engagement model
A structured, phased approach from assessment to production-ready automation.